인터넷 통신 Internet Communication
- 클라이언트 : 데이터 요청하는 컴퓨터
- 서버 : 데이터를 응답해주는 컴퓨터
=> 개념상 구분일 뿐 실제로는 둘다 가능
IP
- 각각의 컴퓨터를 구분해주는 주소를 아이피
- 서로의 IP를 알아야 데이터를 주고 받을 수 있음
- 패킷을 통해 데이터를 주고받음
패킷
인터넷 전송데이터는 모두 패킷이라는 공간 안에 담겨서 전송됨
패킷 속에 데이터를 전송한 컴퓨터의 주소 (출발지 IP), 데이터를 받는 쪽의 주소 (도착지 IP)가 함께 기록
IP의 한계
1. 비연결성
- 비연결성이란 패킷을 받을 대상이 없거나 서비스가 불능인 상태에서도 패킷을 전송
2. 비신뢰성
- 비신뢰성이란 패킷이 중간에 사라지거나 패킷의 순서가 보장되지 않는 것을 의미
3. 프로그램 구분 불가능
- IP 프로토콜의 문제는 같은 컴퓨터에서 여러 개의 애플리케이션이 데이터를 보내도 받는 쪽에서 구분을 못함
ex) 카카오톡에서 전송한 문자메시지와 디스코드에서 전송한 문자메시지를 받는 쪽에선 구분 불가
TCP (Transmission Control Protocol)
- IP가 단순한 데이터 전송에만 집중한다면 TCP는 데이터가 정확하고 순서에 맞게 안정적으로 전송되었는지에 집중
- TCP의 특징
- 연결성
- 신뢰성
- 데이터 전달 순서 보장
** TCP는 데이터 전송시 포트정보를 포함
- TCP는 데이터를 보내기 전에 IP에서 생성한 패킷정보에 추가로 세그먼트를 생성
- 세그먼트에는 패킷에 적혀있는 IP정보에 추가로 PORT정보와 전송 제어, 순서, 검증 정보를 포함
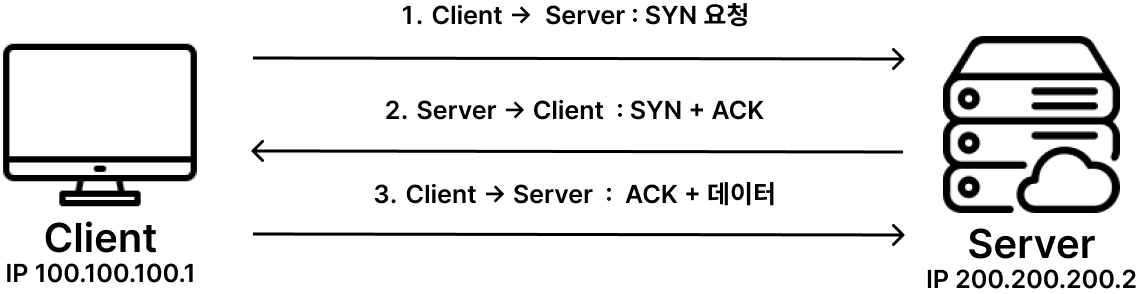
3-way-handshake
- 클라이언트가 서버에게 접속 요청 (SYN)
Client → SYN → Server - 서버는 클라이언트에게 응답(ACK) + 클라이언트 접속 요청(SYN)
Server → SYN + ACK → Client - 클라이언트는 SYN + ACK 확인 후 서버에게 데이터(ACK)를 보내 연결 성립
Client → ACK → Server
** SYN (Synchronize Sequence Number) : 시퀀스 넘버를 랜덤으로 설정하여 세션 연결에 사용, 연결 생성 flag
** ACK (Acknowledgement) : 패킷을 받았는 지 의미하는 flag로 ACK 넘버가 유효한지 표현
포트
- 각 프로그램(애플리케이션)들을 구분해주는 번호
ex) 동시에 카톡, 멜론, 유튜브를 사용하고 있다면
각 애플리케이션들은 다른 포트 번호를 부여받고 서로를 구분
PORT 번호
0~1023 : Well-Known Port (잘 알려진 포트) 0~65535 : 할당 가능 범위
- FTP - 20, 21
- SSH - 22
- HTTP - 80
- HTTPS - 443
- 웰노운포트란 미리 다른 곳에서 선점하고 있는 포트번호
- 커스텀포트번호로 사용하지 않는 것을 권장



DNS (Domain Name System)
- 웹사이트의 서버 주소는 IP 주소로 이루어져 있고 통신 규약이라 53.401.33.1과 같은 숫자들의 조합
- 이러한 숫자는 사용자 입장에선 기억하기 힘들다는 단점이 있습니다.
- 이럴 때 숫자로 된 아이피 주소를 기억하기 쉬운 문자열로 변환해주는 시스템을 DNS
ex) 전화번호 대신 연락처에 저장한 이름으로 검색하여 사용

URI Uniform Resource Identifier
- URI란 단어자체의 뜻을 보면 자원을 식별하는 통일된 방법
- URI는 URL(위치)과 URN(이름)으로 구분
- 일반적으로 URN은 잘 사용되지 않으며 우리가 흔히 알고 있는 링크주소는 URL을 의미
- 실제로 URI를 이야기하면 URL을 의미
URI 구성
scheme://[userinfo@]host[:port][/path][?query][#fragment]
https://search.naver.com:443/search.naver?query=hello&fbm=0



| URI 구성 | 설명 |
| scheme | - 주로 프로토콜이 사용됨 ex) http, https, ftp - 데이터베이스의 경우 DBMS이름이 표기 ex) mysql://, mariadb:// |
| userinfo | - 사용자 정보를 포함해서 인증정보로 활용할 수 있으나 거의 사용되지 않음 - 생략 가능 |
| host | - 서버의 호스트명이며 서버의 IP주소나 도메인명을 사용 |
| port | - 서버 컴퓨터에서 구동중인 서버 애플리케이션의 포트번호를 입력 - 생략시 scheme에 따른 기본값이 설정됨 - http: 80, https: 443 |
| path | - 서버의 자원에 접근하는 경로 ex) /img/animal/dog.jpg, /user/login |
| query | - 서버에 제출하는 데이터 - key=value 형태로 표현 - ?로 시작해서 작성하며 &로 연결해서 추가 가능 - query string, query parameter ex) /coffee/order?type=latte&shot=3&milk=low-fat&size=grande |
| fragment | - 북마크 등의 용도로 사용되나 서버로 전송하는 데이터는 아님 |
HTTP Hyper Text Transfer Protocol
- html문서와 텍스트, 이미지, 음성, 영상, 파일과 더불어 json이나 xml과 같은 데이터 모두를 전송할 수 있는 프로토콜
HTTP 특징
- 클라이언트 서버 구조
- 클라이언트(요청) ↔ 서버(응답)
- 하나의 요청에 하나의 응답을 생성 - 무상태 프로토콜
- 한번의 요청과 한번의 응답이 끝나면 서버는 모든 기억을 삭제
- 무상태성 : 서버가 클라이언트의 상태를 보존하지 않는 것
- 상태 유지를 위해 쿠키, 세션, 토큰과 같은 기술 사용 - 비연결성
- HTTP는 클라이언트가 한번 요청을 한 이후 한번의 응답을 하고 나면 TCP 연결을 바로 끊음
- 지속적으로 연결을 유지하지 않기 때문에 네트워크 자원 효율적으로 사용 가능 - HTTP Message
- HTTP는 요청과 응답을 message를 통해 처리하고 메시지는 표준 규격을 가져 항상 일정한 패턴으로 수행
- 구성: start line (프로토콜, 상태코드) | header (메타데이터) | body (html)
참고 - 단순성, 확장 가능성

HTTP 헤더
- HTTP 헤더는 클라이언트와 서버 간의 통신 과정에서 요청(request)과 응답(response)의 메타데이터를 포함하는 필드
- 키-값(key-value) 쌍으로 구성
- 헤더를 통해 상호간에 데이터의 형식, 인증 정보, 캐싱 정책 등에 대한 정보를 교환
상태 코드 HTTP Status Code
| 상태코드 | 설명 | |
| 100 | 100 Continue | 서버가 요청을 수신했으며 클라이언트가 계속 진행해도 됨 |
| 101 Switching Protocols | 클라이언트가 요청한 프로토콜 전환에 서버가 동의한 경우 | |
| 200 | 200 OK | 요청 성공적으로 처리 |
| 201 Created | 요청 성공 & 새로운 리소스 생성 | |
| 300 | 300 Multiple Choices | 요청에 대한 여러 처리 옵션이 가능한 경우 |
| 301 Moved Permanently | 요청한 리소스의 URI가 영구적으로 변경됨 | |
| 302 Found | 요청한 리소스가 일시적으로 다른 위치에 있음 | |
| 400 | 400 Bad Request | 클라이언트의 요청이 잘못된 형식으로 전달된 경우 |
| 401 Unauthorized | 인증이 필요한 리소스에 대한 요청을 인증 없이 전달한 경우 | |
| 403 Forbidden | 클라이언트가 요청한 리소스에 대한 접근권한이 없는 경우 | |
| 404 Not Found | 요청한 리소스를 찾을 수 없는 경우 | |
| 429 Too Many Request | 클라이언트가 일정 시간 동안 너무 많은 요청을 보낸 경우 (DDoS) | |
| 500 | 500 Internal Server Error | 서버가 요청 처리 실패. 일반적으로 서버 측 문제 |
| 502 Bad Gateway | 서버가 게이트웨이 역할을 하는 경우 상위 서버로부터 유효하지 않은 응답 받은 경우 | |
| 503 Service Unavailable | 서버가 일시적으로 요청 처리 불가. 서버의 과부하나 유지보수 작업으로 인한 것 | |
| 504 Gateway Timeout | 서버가 게이트웨이 역할을 하는 경우 상위 서버로부터 응답받지 못하고 시간초과 |

* HTTP 메시지 출처 : https://www3.ntu.edu.sg/home/ehchua/programming/webprogramming/HTTP_Basics.html
웹서버 vs 웹어플리케이션 서버
| 웹서버 | 웹어플리케이션서버 | |
| 설명 | - 클라이언트로부터 HTTP 요청을 받아들이고, 그에 대한 응답 을 생성하여 반환하는 프로그램 - 웹 서버는 정적 파일(HTML, 이미지, CSS 등)을 제공하는 데 에 주로 사용 |
- 동적 웹 어플리케이션(예: 쇼핑몰, 은행, 메시징 등)을 실행하는 데 사용되는 프로그램 - 웹 어플리케이션 서버는 웹 서버와는 달리 동적인 컨텐츠(데이터베이스 결과, 비즈니스 로직 등) 처리 - 서버 측 스크립트(예: JSP, PHP, ASP.NET 등)를 실행 |
| 통신 과정 |
|
|
| 콘텐츠 유형 |
요청에 따라 기존 리소스를 찾아서 반환 (정적) 실시간 변경 불가 ex) 이미지파일, PDF, 비디오 및 HTML파일 |
실시간으로 생성한 콘텐츠 반환 (동적) 서버 측에서 프로그래밍 처리해서 반환 ex) 사용자 지정된 데이터 표현, 개인화된 UI, DB결과 |
| 프로그래밍 언어 | 프로그래밍 언어 x | 프로그래밍 언어 포함 |
| 프로토콜 | HTTP, FTP, SMTP | HTTP, FTP, SMTP, RMI, RPC ... |
| 멀티 스레딩 |
일반적으로 지원 X | 지원 O, 병렬처리 가능 외부 리소스 필요 시 별도의 스레드를 사용해 상호작용 |
| 프로그램 | Apache, Nginx, IIS | Tomcat, JBoss, WebSphere, WebLogic |
웹 서버와 웹 어플리케이션 서버의 작동
1. 클라이언트의 새 요청은 항상 웹 서버에 먼저 수신
2. 웹 서버에서 생성 가능한 경우 HTTP 응답 또는 사용자 요청 데이터가 캐시에 이미 있는지 확인
3. 웹 서버에서 불가능한 경우 해당 요청을 WAS에 전달
출처 AWS
웹서버와 웹 어플리케이션 서버를 분리하는 이유
1. 확장성 : 독립적으로 필요한 부분만 확장 가능
2. 보안성 : 웹 서버는 리버스 프록시로 동작하며 클라이언트와 WAS 사이에서 장벽 역할
3. 유지보수성: 둘 중 하나의 서버에 문제가 생겨도 대응이 쉬워짐


